4. Multi-Layer Perceptron
Contents
4. Multi-Layer Perceptron#
This notebook is part of a larger effort to offer an approachable introduction to models of the mind and the brain for the course “Foundations of Neural and Cognitive Modelling”, offered at the University of Amsterdam by Jelle (aka Willem) Zuidema. The notebook in this present form is the result of the combined work of Iris Proff, Marianne de Heer Kloots, and Simone Astarita.
Instructions#
The following instructions apply if and only if you are a student taking the course “Foundations of Neural and Cognitive Modelling” at the University of Amsterdam (Semester 1, Period 2, Year 2022).
Submit your solutions on Canvas by Tuesday 29th November 18:00. Please hand in the following:
A copy of this notebook with the code and results of running the code filled in the required sections. The sections to complete all start as follows:
### YOUR CODE HERE ###
A separate pdf file with the answers to the homework exercises. These can be identified by the following formatting, where n is the number of points (out of 10) that question m is worth:
Homework exercise m: question(s) (npt).
Introduction#
Last week we studied Hopfield nets, that consisted of McCulloch-Pitts units. This week, we will analyse those units in more depth. Then, we will see how to combine many neurons to build feed-forward networks called multi-layer perceptrons.
We will need the numpy, pandas, matplotlib, MNE, scipy, pywt and sklearn libraries, as well as some functions that are defined in the MLP.py file and some objects loaded in the EEG.py file. The cell below takes care of all of this.
The following will appear:
Do you want to set the path: /root/mne_data as the default EEGBCI dataset path in the mne-python config [y]/n?
Simply press “y” (on your keyboard) and then “Enter”.
# Install missing package
!pip install mne
# Import packages
import numpy as np # algebra
import pandas as pd # data manipulation
import matplotlib.pyplot as plt # plotting
import mne # EEG dataset
import scipy # scientific computing & signal processing
import pywt # wavelet transform
import random # shuffling lists
import sklearn # machine learning tools (feature selection)
# Download code from the FNCM github repository
!wget --no-cache {"https://raw.githubusercontent.com/clclab/FNCM/main/book/Lab4-materials/EEG.py"}
!wget --no-cache {"https://raw.githubusercontent.com/clclab/FNCM/main/book/Lab4-materials/MLP.py"}
# Import said code
import MLP
from MLP import MLP, plot_errors
import EEG
from EEG import full_epochs, cropped_epochs, EEG_imagery
1. Classification and regression#
In supervised learning a training dataset \(\{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\}\) is given, and the task is to find a function \(y = f(x)\) such that the function is applicable to unknown patterns \(x\). Based on the nature of \(y\), we can classify those tasks into two classes:
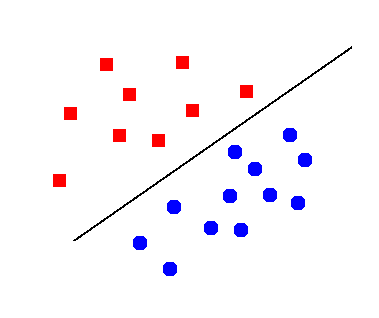
Classification is to assign a predefined label to an unknown pattern. For instance, given a picture of an animal, we need to identify if that picture is of a cat, a dog or a mouse. If there are two categories (or two classes), the problem is called binary classification; otherwise, it is multi-class classification. For the binary classification problem, there is a special case, where patterns of the two classes are perfectly separated by a hyperplane (see Figure 1). We call the phenomenon linear separability, and the hyperplane decision boundary.
Regression differs from classification in that what we need to assign to an unknown pattern is a real number, not a label. For instance, given the height and age of a person, can we infer their weight?
Figure 1: Example of linear separability#
2. Perceptron#
A perceptron is a simplified neuron receiving inputs as a vector of real numbers, and outputting a real number (see Figure 2).
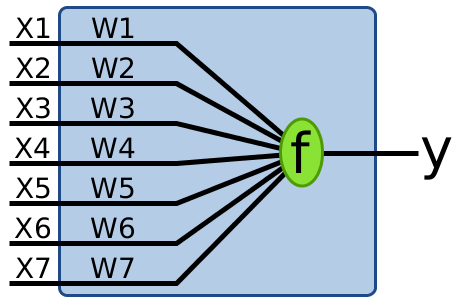
Figure 3: Threshold binary activation function#
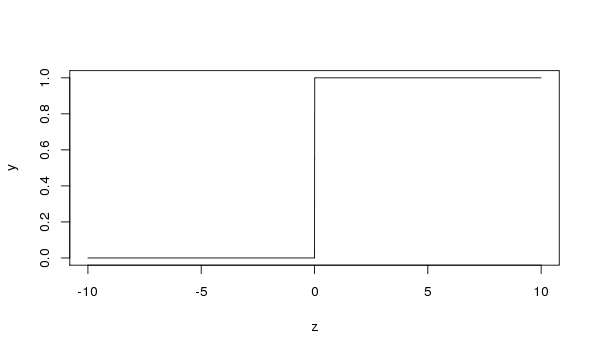
\( f(z) = \begin{cases} 1 & \text{if } z > 0 \\ 0 & \text{otherwise} \end{cases} \)
Mathematically, a perceptron is represented by the following equation:
where \(\mathbf{w} = (w_1, ..., w_n)\) are weights, \(b\) is a bias, \(\mathbf{x} = (x_1, ..., x_n)\) are input nodes, and \(f\) is an activation function.
We are going to implement and train a perceptron in this assignment. Have a look at the function definitions in the next code block.
sigmoidandbinary_thresholdcan be used as activation functions. For the present, we will use the threshold binary function for \(f\) (see Figure 3).
Verify that the function
binary_thresholdimplements this equation.
The other functions are defined as part of the Perceptron class. You can read about classes here but you don’t need to worry about them too much – examples of how to use the Perceptron functions are given in the next code blocks below.
When a
Perceptronobject is created, it initializes a perceptron model with a vector ofweights(\(\mathbf{w}\)), abiasterm (\(b\)), and anactivationfunction (\(f\)).The
compute_errorfunction computes the mean squared error of the perceptron model on a dataset. The mean squared error (\(\text{MSE}\)) and classification accuracy on a sample \(D = \{(\mathbf{x}_1, y_1), ..., (\mathbf{x}_n, y_n)\}\) are respectively defined as
where \(I_u(v)\) is an identity function, which returns 1 if \(u = v\) and 0 otherwise.
The
trainfunction will train the perceptron model on a dataset for a given number of iterations. Theplotfunction is used to visualize the progress of the model during training: it displays the dataset and the current decision boundary.The
updatefunction should apply the update for a single training instance. You need to complete the implementation of this function in the following exercises.
Homework exercise 1: Explain why the \(\text{accuracy}\) is the same as \(1 - \text{MSE}\) on a binary classification task. Hint: look at all possible values of \(y\) and \(\hat{y}\) rather than attempting algebraic manipulation. (1pt)
2.1 Data & Model#
We will start using a very simple dataset to train the perceptron model on: logical OR. This dataset consists of four training examples; have a look at it in the cell below.
# OR data
data_OR = pd.DataFrame(data={'x1': [1, 1, 0, 0],
'x2': [1, 0, 1, 0],
'y': [1, 1, 1, 0]})
data_OR
Now create a dataset for a different operation: XOR. Copy the code for the OR dataset from above, but change the values of y such that the dataset expresses the XOR operation.
# XOR data
### YOUR CODE HERE ###
# data_XOR = ...
data_XOR
We now implement the functions sigmoid and binary_threshold, and the Perceptron class. The update method, i.e. a function for the class, is not correctly implemented yet though: the model as it is learns nothing. We will look at how do it later on.
# sigmoid function
def sigmoid(x):
"""
Sigmoid function.
Input:
x -- an array
Output:
sigmoid(x) = 1/(1 + exp(-x))
"""
return 1./(1. + np.exp(-x))
# binary threshold function
def binary_threshold(x):
"""
Binary threshold function.
Input:
x -- an array
Output:
binary_threshold(x) = 1.0 if x > 0, else 0.0
"""
return 1.*(x > 0)
### Perceptron model
class Perceptron:
def __init__(self, dim, activation):
"""
Initializes the perceptron -- sets weights, bias and
activation function; returns the perceptron object.
Input:
dim -- dimensionality of the datapoints (integer)
activation -- the desired activation function (function)
"""
# initialize all weights and bias as zero
self.weights = np.random.uniform(low=0., high=0., size=dim)
self.bias = np.random.uniform(low=0., high=0., size=1)
# activation function
self.activation = activation
def compute_error(self, X, y):
"""
Computes the error of the perceptron with regard to the dataset.
Input:
X -- an (N, D) array in which each row is a data point
y -- an (N, 1) array in which each row is the target of X[i,]
Output:
classification error (mean squared error)
"""
# number of data points
N = len(X)
# compute mean squared error
mse = np.sum((y.flatten() - \
self.activation(X @ self.weights + self.bias))**2) / N
return mse
def plot(self, X, y, example_input):
"""
Plot the data points and the (learned) decision boundary.
"""
targets = y.flatten()
wmin = -1.5
wmax = 1.5
# plot data points
plt.plot(X[targets == 1, 0], X[targets == 1, 1], 'bo', ms=10)
plt.plot(X[targets == 0, 0], X[targets == 0, 1], 'rs', ms=10)
plt.xlim(wmin, wmax)
plt.ylim(wmin, wmax)
plt.xticks([0, 1])
plt.yticks([0, 1])
plt.xlabel('$x_1$', size=15)
plt.ylabel('$x_2$', size=15)
# plot circle around current example
plt.scatter(example_input[0], example_input[1], marker='s',
color='none', edgecolor='g', s=400)
# plot decision boundary
if perceptron.weights[0] == 0. and perceptron.weights[1] == 0:
pass
elif perceptron.weights[1] == 0.:
db_y = np.arange(start=wmin, stop=wmax, step=0.1)
db_x = (-perceptron.bias - db_y*perceptron.weights[1]) / \
perceptron.weights[0]
plt.plot(db_x, db_y, 'k-')
else:
db_x = np.arange(start=wmin, stop=wmax, step=0.1)
db_y = (-perceptron.bias - db_x*perceptron.weights[0]) / \
perceptron.weights[1]
plt.plot(db_x, db_y, 'k-')
plt.show()
def train(self, X, y, maxit=5, learn_rate=0.1, stepbystep=True):
"""
Trains the perceptron -- iterates over a dataset and learns
online.
Input:
X -- an (N,D) array in which each row is a data point
y -- an (N,1) array in which each row is the target of X[i,]
maxit -- the number of iterations for training
learn_rate -- the learning rate for training
stepbystep -- wait for user to continue and print each step
Output:
errors -- error over the entire data after each iteration
"""
errors = np.zeros(maxit)
for it in range(0, maxit):
if stepbystep:
print('iteration', it+1)
# pick training example
i = it % len(X)
example_input = X[i,:]
example_target = y[i]
# update perceptron
self.update(example_input, example_target, learn_rate, stepbystep)
if stepbystep:
self.plot(X, y, example_input)
inpt = input()
if inpt == 'q':
print('Stopped after', it+1, 'iterations.')
break
errors[it] = self.compute_error(X, y)
return errors
def update(self, example_input, example_target, learn_rate, stepbystep=True):
"""
Applies a single update to the perceptron.
Input:
example_input -- an example datapoint (vector)
example_target -- the corresponding target
learn_rate -- the learning rate (real number)
stepbystep -- whether to print the results
"""
### YOUR CODE HERE ###
## TODO: make proper prediction
pred = 0 ## ...
## TODO: write update rules for weights and bias
self.weights = self.weights ## + ...
self.bias = self.bias ## + ...
######################
if stepbystep:
print('\tinput:', example_input)
print('\ttarget:', example_target)
print('\tprediction:', pred)
print('\tweights:', self.weights)
print('\tbias:', self.bias, '\n')
The code block below loads the data and runs the training for the perceptron. Use stepbystep to see the prediction and model parameters after each example. At the same time, a plot will appear to inform you which example (encased in the green box) is being taken, and what the current decision boundary (the black line) looks like. Press Enter inside the input field to go to the next iteration, and you may press “q” if you want to stop the code before the maximum number of iterations is reached.
If you run the code, you should now see that the model is not learning the task yet: you will not see a moving decision boundary. You need to implement the update function, which you can find in the cell above: Subsection 2.2 and subsection 2.3 will tell you how.
# the data
# change between data_OR and data_XOR based on what you want to learn
data = data_OR
# shuffle data
np.random.shuffle(data.values)
X = data[['x1', 'x2']].values
y = data[['y']].values
input_size = X.shape[1]
# initialize the perceptron
perceptron = Perceptron(dim=input_size,
activation=binary_threshold)
# print model attributes before training
print('weights:', perceptron.weights)
print('bias:', perceptron.bias)
print('activation function:', perceptron.activation.__name__)
# train perceptron
perceptron.train(X, y,
maxit=15,
learn_rate=0.1,
stepbystep=True)
2.2 Prediction#
A new pattern \(\mathbf{x}\) will be assigned the label \(\hat{y} = f(\mathbf{w}^T \mathbf{x} + b)\).
Look at the code block above that implements the Perceptron class and find the corresponding variables in the code for all elements of the mathematical notation. What are the variable names for the weights (\(\mathbf{w}\)), the bias term (\(b\)), an example input pattern (\(\mathbf{x}\)), and the activation function \(f\), in the provided Python code?
Rewrite the “
pred = 0” line in theupdatefunction of the perceptron model, such that the variablepredgets assigned the appropriate value according to this equation. Hint: you may want to use thenp.sumfunction which returns the sum of all its input values.
2.3 Training#
Traditionally, a perceptron is trained in an online-learning manner with the delta rule: we randomly pick an example \((\mathbf{x}, y)\) and update the weights and bias as follows:
where \(\eta\) is a learning rate (\(0 < \eta < 1\)), \(\hat{y}_\text{old}\) is the prediction based on the old weights and bias.
Implement these weight update rules in the
updatefunction of the perceptron model, by rewriting these lines in the code cell:
self.weights = self.weights ## + ...
self.bias = self.bias ## + ...
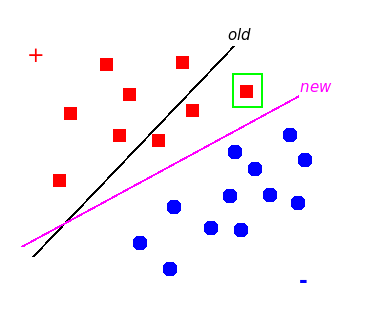
The weights and bias are only updated if the prediction \(\hat{y}_\text{old}\) is different from the true label \(y\), and the amount of update is (negatively, in the case \(y = 0\)) proportional to \(\mathbf{x}\). Intuitively, the update is to pull the decision boundary to a direction that makes the prediction on the example “less incorrect” (see Figure 4). It can be proven that if the training dataset is linearly separable, the perceptron is guaranteed to find a hyperplane that correctly separates the training dataset (i.e., error = 0) in a finite number of update steps. Otherwise, the training won’t converge.
Figure 4: Example of weight update#
The chosen example is enclosed in the green box. The update pulls the plane to a direction that makes the prediction on the example “less incorrect”.
Training on OR#
Now train your model on the OR data to learn the logical OR operation: re-run the code block that defines the perceptron functions (with your rewritten update function), and then re-run the code block for training the perceptron. Make sure you understand how the model learns by computing the prediction and update yourself (on paper) for each time step.
Homework exercise 2: In how many iterations does the training converge? Does the answer depend on the order of the examples? Explain. (1pt)
Training on XOR#
Now train a perceptron model on your XOR data. In the code block for training the perceptron, rewrite the line data = data_OR so that it loads the XOR dataset that you created.
Homework exercise 3: What can you conclude about the convergence of training? Explain the observed behaviour. (1pt)
3. Multi-layer perceptron#
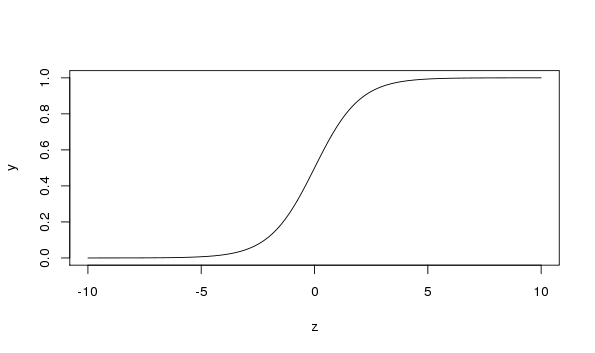
The perceptron model presented above is very limited: it is theoretically applicable only to linearly separable data. In order to handle non-linearly separable data, the perceptron is extended to a more complex structure, namely the multi-layer perceptron (MLP). An MLP is a neural network in which neuron layers are stacked such that the output of a neuron in a layer is only allowed to be an input to neurons in the upper layer (see Figure 5). Informally speaking, a neuron is activated by the sum of weighed outputs of the neurons in the lower layer. It turns out that, if the activation functions of those neurons are non-linear, such as the sigmoid (or logistic) function (see Figure 6):
then the MLP can capture high non-linearity of data: it can be proven that we can approximate any continuous function at an arbitrary small error by using complex-enough MLPs.
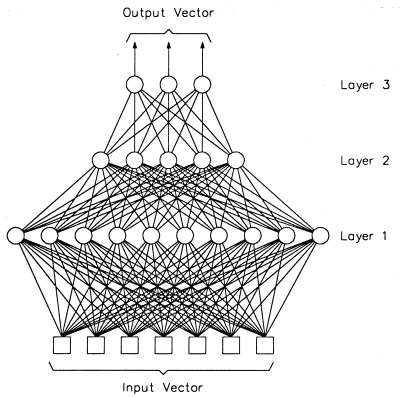
Figure 6: Sigmoid activation function#
3.1 Prediction#
Prediction is very fast thanks to the feedforward algorithm (Figure 7, on the left). The algorithm says that, given \(\mathbf{x}\), we firstly compute the outputs of the neurons in the first layer; then we compute the outputs of the neurons in the second layer; and so on until we reach the top layer.
Figure 7: Feedforward (left) and backpropagation (right)#
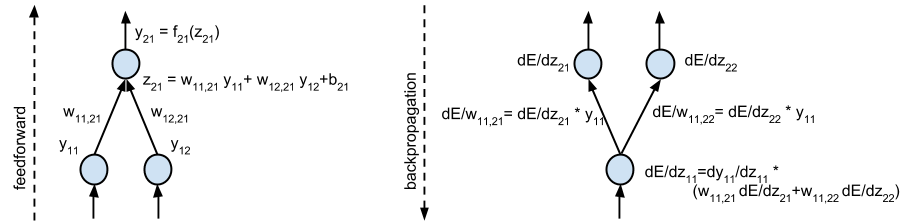
3.2 Training#
Training an MLP is to minimize an objective function, which is related to the task that the MLP is used for. For instance, for the binary classification task, the following objective function is widely used:
where \(D\) is a training dataset, \(\hat{y}\) is the output of the MLP given an input \(\mathbf{x}\) and \(\theta\) is its set of weights and biases. In order to minimize the objective function \(J(\theta)\), we will use the gradient descent method (see Figure 8) which says that an amount of update for a parameter is negatively proportional to the gradient at its current value.
Figure 8: Illustration for the gradient descent method#
The blue line is the tangent at the current value of the parameter \(w\). If we update \(w\) by subtracting an amount proportional to the gradient at that point, the value of \(E\) will be pushed along the arrow and hence decrease. However, this method only guarantees to converge to a local minimum.

We will now train a multi-layer perceptron on the OR and XOR data. The MLP itself is already implemented for you, as well as the feedforward and backpropagation algorithms for training it (if you want, you can have a look at the code in the MLP.py file). Here we will just load the MLP and experiment with a few settings. When you execute the codeblock below, you will see the MLP’s final accuracy on the training dataset, in addition to a plot of the progress over training. This plot shows the weighed sum of squared errors at each iteration:
It is different from the MSE that we saw earlier. For one, it computes the sum instead of the mean of the errors. Secondly, the sum is weighed with respect to the class sizes. In many datasets, the size of the different classes varies. There may be more pictures of cats than of dogs, for instance. The weighing factor compensates for this, so that a model that always predicts “cat” has no better performance than a model that always outputs “dog”.
Train an MLP#
Now train the MLP on the OR and XOR datasets by changing and executing the code block below. Experiment by varying the number of iterations, the learning rate, and the number of hidden nodes in order to answer the homework exercises below.
# the data
# change between data_OR and data_XOR based on what you want to learn
data = data_OR
# shuffle data
np.random.shuffle(data.values)
X = data[['x1', 'x2']].values
y = data[['y']].values
input_size = X.shape[1]
# initialize the MLP
mlp = MLP(n_input=input_size,
n_hidden=5,
n_output=1)
# train the MLP on the dataset
errors = mlp.train(X, y,
learn_rate=0.2,
maxit=1000)
# make predictions on the training dataset
predictions = np.array([mlp.predict(X[i,]) for i in range(len(X))])
# compute final accuracy
accuracy = sum((predictions > 0.5).astype(int) == y) / len(y)
print('Final accuracy:', accuracy)
# plot weighed SSE over iterations
plot_errors(errors, 'Weighed SSE')
Homework exercise 4: Find a minimum number of iterations such that the accuracy is 1 for the OR data, then change the learning rate and/or the number of hidden notes twice and report all results. Can you make any qualitative, simple observations about what you see from this experiment? (1.5pt)
Homework exercise 5: How many hidden nodes do you minimally need to learn the XOR function? (0.5pt) Motivate your answer with a theoretical explanation (0.5pt) and an empirical validation. (0.5pt)
4. Training on EEG data#
We will now look at how well the MLP can be trained to classify data that we did not create ourselves, but which were recorded from brain activity. We will use a dataset from the MNE library, which is well-known and widely used for the analysis of neurophysiological data in Python. The dataset (EEGBCI, described at PhysioNet) contains EEG recordings on various tasks, including a motor imagery task: subjects were instructed to imagine moving either their hands or their feet, given some visual cue. We will use the data from one participant performing this task, in 45 trials (21 for hands, 24 for feet), while EEGs were recorded from 64 electrodes across the scalp. First we load the data.
We have loaded the EEG data from 0.5 seconds before the visual cue was presented, until 0.5 seconds after it was presented. The plots below show the raw EEG data for each of the 64 channels, averaged over trials, with the cue presentation at \(t = 0\). Can you see the difference in EEGs between when the subject was thinking of moving their hands vs. moving their feet?
feet_plot = full_epochs['feet'].average().plot()
hands_plot = full_epochs['hands'].average().plot()
We want to see whether the MLP and perceptron can also learn to distinguish these patterns, and thereby predict from an EEG signal which extremities a subject is imaginarily moving. For this we will only use the signals from the point where the subject was actually imagining the movement (\(t = 0\)). Furthermore, we don’t use all datapoints in the raw EEG signal; instead, we compute some features with which we aim to capture the most important information about the wave. For our toy problem, it turns out that an extremely crude encoding of this information will do.
We intend to capture some of the temporal properties of the EEG signal (how the wave changes over time), as well as some spectral properties (how intense the signal is in different frequency bands).
For the temporal properties, we divide the y-axis range of the EEG signal into 3 quantiles (in the plot below, the regions divided by the grey horizontal lines). From every raw EEG wave (the black line), we first remove the noise (giving the blue line), and then compute the average of the transformed signal at a few evenly spread points (blue dots). For each of those dots, we add a 0, 1 or 2 to our list of features depending on what quantile they fall in. Hence, the list of temporal features encoding the signal below would be [0, 1, 1, 0, 0, 0, 1, 2, 2, 2, 2]. The quantiles are computed separately for each channel of every epoch, such that there will be an approximately equal number of points in each of the three ranges — the 0s, 1s and 2s therefore (very crudely!) encode the relative upward and downward movement of the wave over time.
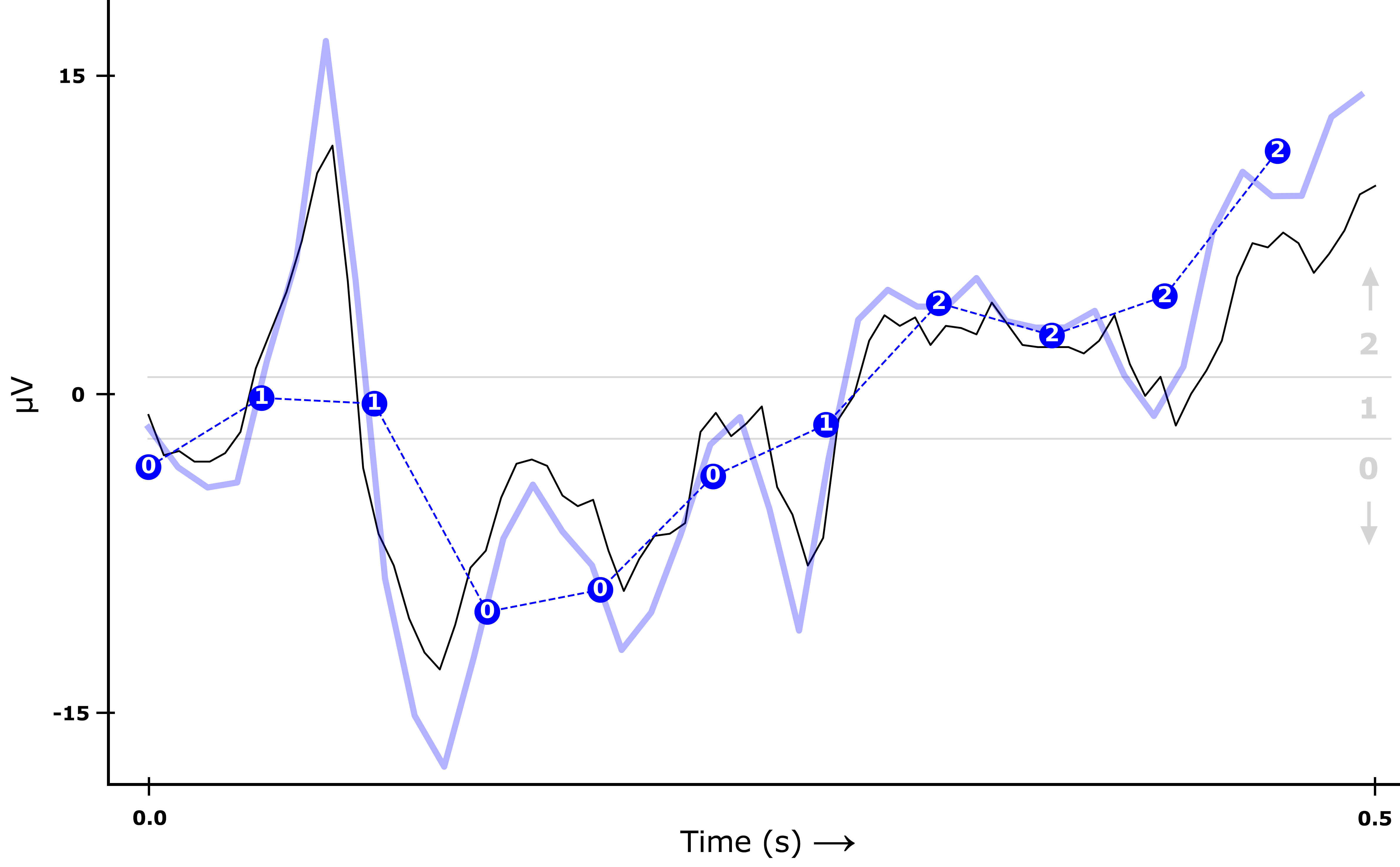
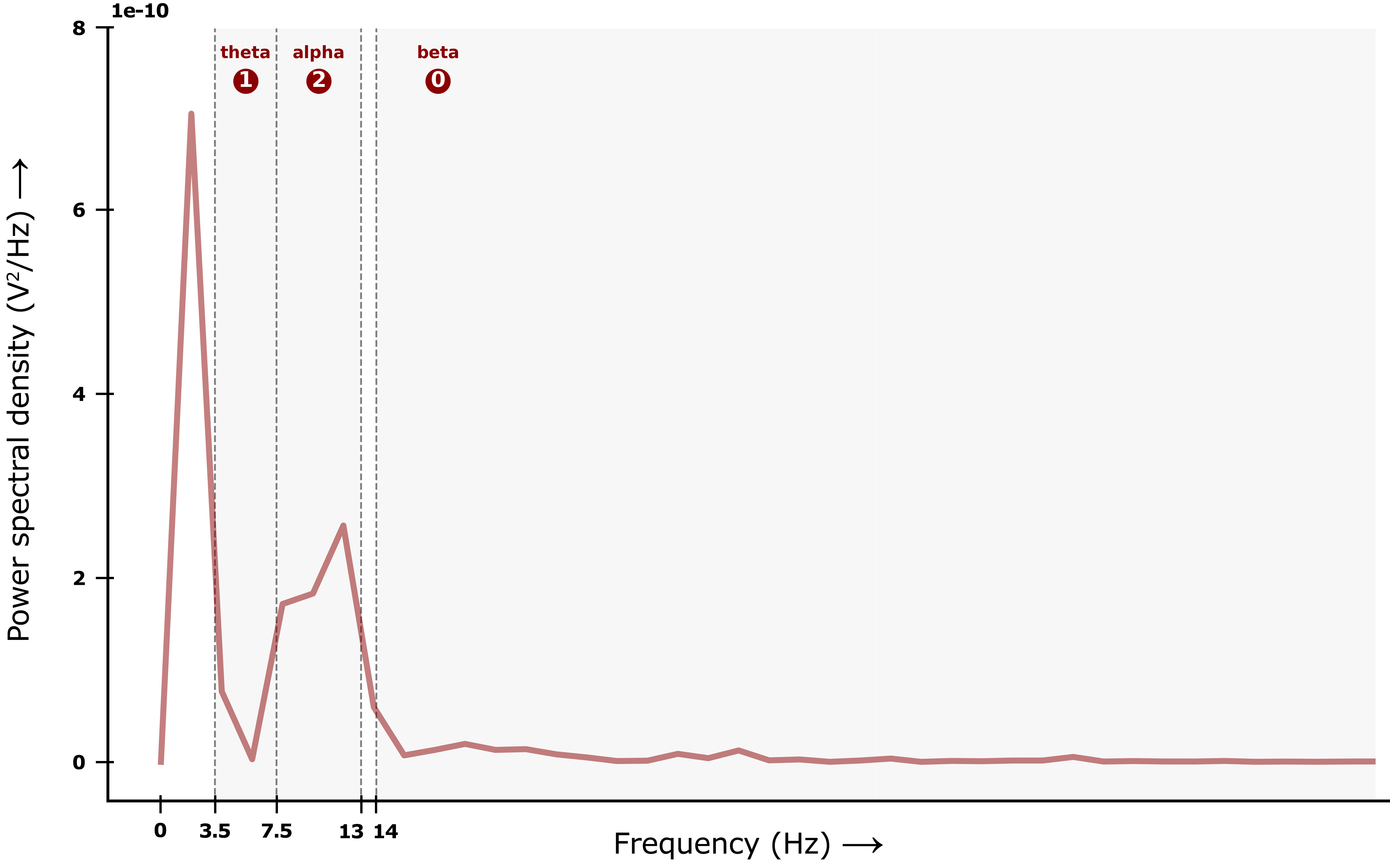
For the spectral properties, we look at three different frequency bands: theta (3.5 - 7.5 Hz), alpha (7.5 - 13 Hz) and beta (14+ Hz). We want to encode the relative distribution of spectral power density in these three bands: which frequency band contains most movement, and which the least? Again, we encode this using 0, 1 and 2: this time, the numbers mean “least”, “middle” and “most” spectral power density. The plot below shows the spectral power density for different frequency ranges across the entire signal timeframe. For this signal, the alpha band has the highest power density, followed by theta and finally beta. The list of spectral features encoding this signal would therefore be [1, 2, 0].
Ultimately, we select the best of all spectral and temporal features across trials, such that we end up with a list of 96 numbers (all 0s, 1s and 2s) encoding the EEG signal per trial. You don’t need to understand the specifics of the feature extraction and selection procedure (although you can have a look in the EEG.py file if you’re curious), but you can probably see that these features omit a lot of information from the EEG signal. Maybe you can even already think of better ways to represent this information. Nevertheless, these very crude representations may still provide enough information for the MLP to learn to distinguish between imagined hand or foot movement.
To see how well the MLP model can learn to do this classification, we split the data into a training and a test set: we will train the model on two thirds of the data, and then test its prediction accuracy on the other third. As such, we evaluate how well the learned decision boundary (in this case a manydimensional hypersurface) will generalize to correctly classify unseen data: this method of model validation is called cross-validation.
# shuffle data
idx = list(range(len(EEG_imagery['trial_numbers'])))
random.shuffle(idx)
EEG_imagery['trial_numbers'] = EEG_imagery['trial_numbers'][idx]
EEG_imagery['features'] = EEG_imagery['features'][idx]
EEG_imagery['labels'] = EEG_imagery['labels'][idx]
# split 2/3 to train & test set
trials_train = EEG_imagery['trial_numbers'][:30]
trials_test = EEG_imagery['trial_numbers'][30:]
X_train = EEG_imagery['features'][:30]
X_test = EEG_imagery['features'][30:]
y_train = EEG_imagery['labels'][:30]
y_test = EEG_imagery['labels'][30:]
The code block below trains the MLP, plots the error over training and prints the final accuracy on the test set.
# train MLP & plot training error
mlp = MLP(n_input=96,
n_hidden=5,
n_output=1)
errors = mlp.train(X_train, y_train,
maxit=100, learn_rate=0.1)
plot_errors(errors, 'Weighed SSE')
# make predictions on test set
predictions = np.array([mlp.predict(X_test[i]) for i in range(len(X_test))]).flatten()
accurate = ((predictions > 0.5).astype(int) == y_test)
accuracy = sum(accurate) / len(y_test)
print('Final accuracy:', accuracy)
Homework exercise 6: Train the MLP on the EEG dataset a few times while varying the parameters; you can vary the number of hidden nodes and the training parameters
maxitandlearn_rate.A. Run the training several times with the same settings. Do you get the same results every time? Why or why not? (0.5pt)
B. Training on the EEG data, how does the number of hidden nodes relate to the accuracy? Note: for proper empirical justification, you need to take the average over several runs. You may include a table or a plot to report your findings. (1pt)
C. What can you conclude about the relation between convergence speed, learning rate and number of hidden nodes? (1.5pt)
### YOUR CODE HERE ###
# copy and paste the code form the cell above, but change the values for n_hidden, maxit, and learn_rate
If your model does not achieve 100% accuracy on the test set, it can be worth exploring the specific test set items that led to an incorrect prediction: can we find the reason that the MLP assigned these trials to the wrong class? Do they also look particularly confusing to us?
The cells below plot the EEG trials assigned to the training set, i.e. the epochs based on which the MLP learned to distinguish hands vs. feet in the motor imagery data. Note that the epochs here are cropped from the moment of cue presentation \((t = 0)\). We again separately plot the training set epochs (averaged over trials) for imagined feet movement vs. imagined hand movement.
# Plot epochs in training set for feet (labeled 0)
feet_trials = trials_train[np.where(y_train == 0)]
train_feet_plot = cropped_epochs[feet_trials].average().plot()
# Plot epochs in training set for hands (labeled 1)
hands_trials = trials_train[np.where(y_train == 1)]
train_hands_plot = cropped_epochs[hands_trials].average().plot()
Now, for which unseen epochs did the MLP not manage to make a correct prediction? The code below separately plots the EEG data for each misclassified trial in the test set.
prediction_mistakes = np.where(accurate == False)[0]
for idx in prediction_mistakes:
print('Trial:', trials_test[idx])
print('Prediction:', (predictions[idx] > 0.5).astype(int))
print('Correct label:', y_test[idx])
cropped_epochs[trials_test[idx]].average().plot()
Homework exercise 7: Explore some misclassified epochs from an MLP trained with the default settings (5 hidden nodes, 100 iterations, learning rate 0.1). Can you see why the MLP made a mistake? Explain your observations, and include the epoch plots as illustration. (1pt)