2B: Representational similarity with story reading fMRI data#
by Marianne de Heer Kloots, September 2022
In the first part of this week’s tutorial we saw how the structure of the embeddings space changes over model layers: the embeddings become more contextualized in deeper layers.
Recent work comparing language model activations to human brain measurements suggests that these deeper and more contextualized layers align better with the brain than the earlier layers (for example Caucheteux & King, 2022; Schrimpf et al., 2021). These studies use trained regression models to map from model activations to brain signals, but we can also use RSA to analyze the same phenomenon. Just as we computed the correlation of RDMs from different model layers before, we can now compute the correlation between model and brain RDMs. So is it true that embeddings from later model layers form more brain-like representational spaces, compared to earlier model layers?
To answer this question, we’ll use fMRI scans recorded from one subject in an experiment where subjects read a chapter from the first Harry Potter book (Wehbe et al., 2014). Participants in the experiment were presented with the chapter text through Rapid Serial Visual Presentation (RSVP), meaning that the words of the chapter appeared one by one on a screen, for 500 ms each. The brain scan TR (repetition time) was 2 seconds, meaning that every 2 seconds a 3d brain volume was recorded. This means that (almost*) every scan records the activity of reading 4 words. We’ll therefore also average the embeddings over 4 words on the model side, in order to create so-called ‘TR embeddings’ that give us the same temporal resolution as we have from the participant. In addition, to account for the haemodynamic response delay**, we take the brain scan recorded 4 seconds (2 TRs) after each text presentation as the response to that text. Finally, we restrict ourselves to voxels recorded in the left anterior temporal lobe (LATL), which is generally known to be an important area for semantics and language processing (see e.g. Bonner & Price, 2013, Bemis & Pylkkänen, 2013).
* In practice, the experiment was divided into 4 blocks, and the last scan in each block contains reading activity for only 3 words. In the code below, we provide you with all 1295 TR texts (one on each line in the tr_texts.txt file) and the corresponding 1295 brain responses, so the inputs and recorded activations are aligned correctly.
** The signal recorded in fMRI studies is the so-called Blood Oxygen Level Dependent (BOLD) response, which takes about 4-6 seconds after stimulus presentation to reach its peak. We choose 4 seconds here based on earlier work where we found this to work best for this dataset (Abnar et al., 2019; figure 6).
!pip -q install pathlib wget transformers nilearn
For this part of the tutorial, we import some helper functions from Marianne’s research code for dealing with the fMRI data. If you’re curious to know what is going on under the hood, you can look up any specific function in the fmri_data_loading.py file, or run a code cell with a function name followed by ?. Although some of these functions have different names than the ones we used before, it should be clear that we will be following the same steps overall: computing distance matrices for different layers of our model (and now also for the brain), and then calculate the correlation between them for RSA.
import wget
import os
if not os.path.exists('fmri_data_loading.py'):
wget.download('https://raw.githubusercontent.com/clclab/ANCM/main/lab2/fmri_data_loading.py')
tr_texts_file = 'tr_texts.txt'
if not os.path.exists(tr_texts_file):
wget.download('https://raw.githubusercontent.com/clclab/ANCM/main/lab2/tr_texts.txt')
from transformers import AutoModel, AutoTokenizer
import nilearn.signal
import copy
import matplotlib.pyplot as plt
from fmri_data_loading import *
# load the model and tokenizer
model_name = 'bert-base-uncased'
model = AutoModel.from_pretrained(model_name,
output_hidden_states=True,
output_attentions=True)
# if you want to try a gpt-like model later,
# we'll need these tokenizer settings
if 'gpt' in model_name:
tokenizer = AutoTokenizer.from_pretrained(model_name,
add_prefix_space=True)
tokenizer.pad_token = tokenizer.eos_token
# but this will work for bert
else:
tokenizer = AutoTokenizer.from_pretrained(model_name)
torch.set_grad_enabled(False)
<torch.autograd.grad_mode.set_grad_enabled at 0x7821c83b2080>
Below we download the data from subject 8 in the Wehbe et al. (2014) experiment. You can find more information on this dataset, as well as the data from other subjects, here. In particular, a description of all the information available per subject is available here (the original data is stored in .mat files, which we convert to python dictionaries below, but they contain the same information; you can run the load_subj_dict? cell below to see more information about the structure of the dictionaries).
load_subj_dict?
# download data for subject 8
subj_raw_file = 'subject_8.mat'
if not os.path.exists(subj_raw_file):
url = 'http://www.cs.cmu.edu/~fmri/plosone/files/subject_8.mat'
wget.download(url)
# load into python dictionary
subj_dict = load_subj_dict(subj_raw_file)
# preprocess fMRI signals
subj_cleaned_file = 'subject_8_clean.npy'
if not os.path.exists(subj_cleaned_file):
# preprocessing parameters
cleaning_params = {
't_r': 2, # TR length in seconds
'low_pass': None, # low-pass filter frequency cutoff (Hz)
'high_pass': 0.005, # high-pass filter frequency cutoff (Hz)
'standardize': 'zscore', # standardization method
'detrend': True, # whether to apply detrending
}
cleaned_subj_dict = copy.copy(subj_dict)
cleaned_subj_dict['data'] = nilearn.signal.clean(subj_dict['data'],
runs=subj_dict['time'][:,1],
**cleaning_params)
np.save(subj_cleaned_file, cleaned_subj_dict)
subj_dict = np.load(subj_cleaned_file, allow_pickle=True).item()
Below we select the regions of interest (ROIs) in the left anterior temporal lobe (LATL) from which we will retrieve the brain responses and construct the brain-side RDMs. You can later define another selection of ROIs yourself, if you like (run subj_dict['meta']['ROInumToName'] to see a list of all available ROIs in this dataset, they are based on the AAL Single-Subject atlas).
# subregions of left-anterior temporal lobe
LATL_ROI = ['Temporal_Sup_L', 'Temporal_Pole_Sup_L',
'Temporal_Mid_L', 'Temporal_Pole_Mid_L', 'Temporal_Inf_L',
'Fusiform_L', 'ParaHippocampal_L']
We now have the brain response scans for each of the 1295 text TRs; there are 4210 voxels in our LATL ROI selection.
brain_responses = get_text_response_scans(subj_dict,
delay=2,
ROI=LATL_ROI) # delay in TRs (1 TR = 2 sec)
brain_responses['voxel_signals'].shape
(1295, 4210)
Below we load tr_texts (a list of texts, one for every TR containing the text presented during that TR), and we calculate the number of words presented during each TR (a list of mostly 4s and some 3s). We then split the text into sentences which we will present to our model to extract the embeddings. Note that for BERT, this means that the model will for some TRs have access to the words at the end of the sentence, which the experiment participant hadn’t seen at the time the brain scan was recorded. If you’d like, you can try out different ways of providing input text to the model, for example a fixed text window for each TR excluding words presented after that TR (a way to ‘make BERT causal’ as discussed in the lecture).
tr_texts = open(tr_texts_file, 'r').read().splitlines()
words_per_tr = [len(tr.split(' ')) for tr in tr_texts]
hp_sentences = create_context_sentences(tr_texts)
We process all sentences of the Harry Potter chapter through BERT, and extract the embeddings for each word at every layer. There are 5176 words and 13 ‘layers’ (input embeddings + 12 model layers), which each have a 768-dimensional activation vector for every word.
%%time
# this will take a few minutes
layer_acts_bert = get_layer_activations(model,
tokenizer,
hp_sentences)
layer_acts_bert = np.concatenate(layer_acts_bert)
print(layer_acts_bert.shape)
(5176, 13, 768)
CPU times: user 2min 59s, sys: 1.51 s, total: 3min
Wall time: 3min 10s
Then we average over the words in each TR to get the ‘TR embeddings’:
tr_embeddings_bert = get_tr_embeddings(layer_acts_bert, words_per_tr)
print(tr_embeddings_bert.shape)
(1295, 13, 768)
Now we have activations vectors for each of the 1295 text TRs for each layer of the model. We also have brain responses to each of the 1295 text TRs, so we can create RDMs for both! (13 RDMs for each layer of the model, and 1 RDM for subject 8’s brain responses)
RDMs_bert = [vector_distance_matrix(tr_embeddings_bert[:,layer,:],
metric="cosine")
for layer in range(tr_embeddings_bert.shape[1])]
RDM_brain = vector_distance_matrix(brain_responses['voxel_signals'],
metric="cosine")
print(RDMs_bert[0].shape) # one of the model RDMs
print(RDM_brain.shape) # the brain RDM
(1295, 1295)
(1295, 1295)
We can compute the RSA score (Pearson’s correlation) between each of the model layers and the brain responses now.
rsa_scores_bert = [compute_rsa_score(RDM_brain,
RDMs_bert[layer],
score="pearsonr")
for layer in range(len(RDMs_bert))]
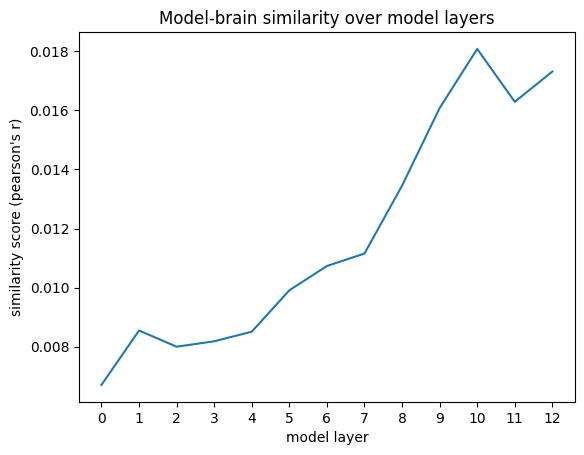
As we see below, the correlation values themselves are quite low (they might get a bit higher if you provide the model with more context text). But we do observe the expected qualitative pattern: the higher layers with more contextualized embeddings score up to twice as high in representational similarity compared to lower layers.
plt.plot(rsa_scores_bert)
plt.xlabel('model layer')
plt.xticks(range(len(rsa_scores_bert)))
plt.ylabel('similarity score (pearson\'s r)')
plt.title('Model-brain similarity over model layers')
plt.show()
ASSIGNMENT (part 1)#
At first sight, the result above seems to nicely confirm the idea that the more contextualized embeddings from middle-to-high model layers show better alignment with human brain responses. But what have we really learned about language processing?
To make sure that this result really captures something about the linguistic processes involved in story reading, we would ideally compare it to some ‘control’ or ‘baseline’ condition where we would not expect the effect to occur. One option would be to compare results with a different brain region that we would not expect to be as much involved in language processing. Another option could be to shuffle the RDMs before computing the RSA scores, such that we compute the correlation between model and brain RDMs for unmatched TRs (you could do this several times to create a ‘null distribution’ of RSA scores). You might also want to see if the result can be reproduced at the group level (comparing RSA scores across individual subjects or computing a mean RDM for several subjects), compute some kind of ‘noise ceiling’ based on RDM-correlation across subjects (Nili et al., 2014), or compare to results using a different model architecture (like GPT-2).
Choose at least one of the options above, and include one (or more) plot(s) in your report comparing the result obtained above to your ‘baseline’ / ‘control’ condition or analysis extension. Then describe your approach in around 200-300 words, focussing on what your analysis teaches us about human brain activity involved in language processing, and answering the following questions:
Do your new results still confirm the idea that contextualized embeddings from middle-to-high model layers show better alignment with language processing in the human brain?
Why is your particular baseline / control / extension important to include in analyses comparing DNN activations and brain responses?
What are some limitations of this particular baseline / control / extension for your analysis (i.e. alternative explanations that it does not rule out yet)?